专栏名称: 人工智能前沿讲习
| 领先的人工智能知识平台 |
今天看啥
微信公众号rss订阅, 微信rss, 稳定的RSS源
目录
相关文章推荐

|
跟宇宙结婚 · 节目更新:跟宇宙结婚悄悄话 vol.236 ... · 昨天 |

|
跟宇宙结婚 · 日常叨叨:上饿了么搜【跟宇宙结婚】领红包哟 · 昨天 |

|
|
跟宇宙结婚 · 日常念叨:上饿了么搜【跟宇宙结婚】领红包哟 · 4 天前 |

从 MaxViT 到 ACC-ViT:视觉 Transformer 的紧凑型网络实现参数与性能的双重优化 !
人工智能前沿讲习 · 公众号 · · 2024-06-24 18:00
推荐文章

|
体坛周报 · 聚焦 | 乒超联赛第一阶段落幕,八支晋级总决赛球队诞生! 3 天前 |
|
|
体坛周报 · 聚焦 | 乒超联赛第一阶段落幕,八支晋级总决赛球队诞生! 3 天前 |
|
|
跟宇宙结婚 · 日常念叨:上饿了么搜【跟宇宙结婚】领红包哟 4 天前 |

|
欧欧量化 · 通达信:抓板块龙头选股指标公式 6 月前 |
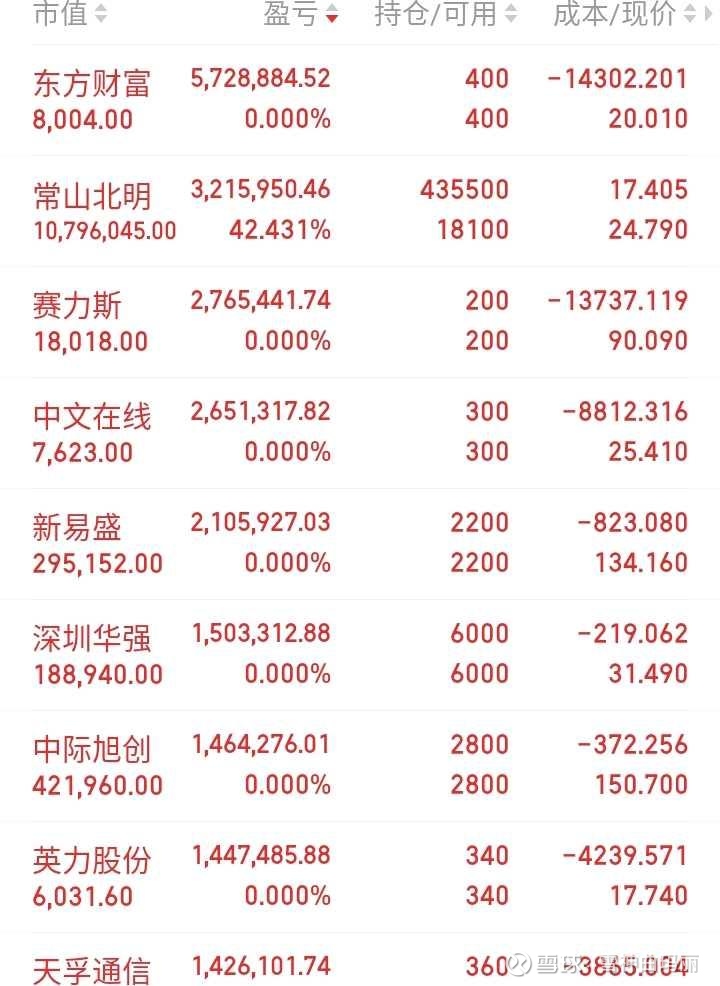
|
雪神曲玛丽 · -20241017144345 2 月前 |

|
正和岛 · 年入5亿,中年男人的“白月光”,要IPO了 2 周前 |