专栏名称: 极市平台
| 极市平台是由深圳极视角推出的专业的视觉算法开发与分发平台,为视觉开发者提供多领域实景训练数据库等开发工具和规模化销售渠道。本公众号将会分享视觉相关的技术资讯,行业动态,在线分享信息,线下活动等。 网站: http://cvmart.net/ |
今天看啥
公众号rss, 微信rss, 微信公众号rss订阅, 稳定的RSS源
目录
相关文章推荐

|
广西商务厅 · 放心用油,安全行车。维护成品油经营秩序,广西 ... · 12 小时前 |
|
|
广西商务厅 · 放心用油,安全行车。维护成品油经营秩序,广西 ... · 12 小时前 |

|
茅酒圈 · 现在的i茅台,预约就中,没有吸引力了? · 15 小时前 |
|
|
茅酒圈 · 现在的i茅台,预约就中,没有吸引力了? · 15 小时前 |

|
NXTV都市阳光 · 提醒|今天起,吃早餐请调整一下 · 昨天 |
|
|
NXTV都市阳光 · 提醒|今天起,吃早餐请调整一下 · 昨天 |

|
题材挖掘君 · 人形机器人,标的公司梳理(精选名单) · 2 天前 |

|
java1234 · 最近,后端的薪资彻底爆了。。。 · 2 天前 |
|
|
java1234 · 最近,后端的薪资彻底爆了。。。 · 2 天前 |

推荐文章
|
|
广西商务厅 · 放心用油,安全行车。维护成品油经营秩序,广西商务为民生利益保驾护航~~ 12 小时前 |
|
|
茅酒圈 · 现在的i茅台,预约就中,没有吸引力了? 15 小时前 |
|
|
NXTV都市阳光 · 提醒|今天起,吃早餐请调整一下 昨天 |
|
|
题材挖掘君 · 人形机器人,标的公司梳理(精选名单) 2 天前 |
|
|
java1234 · 最近,后端的薪资彻底爆了。。。 2 天前 |



|
重庆本地宝 · 好消息!重庆将新建一批学校!有你家附近的吗? 11 月前 |

|
医药笔记 · FibroGen大跌45%:CTGF抗体胰腺癌三期临床失败 11 月前 |
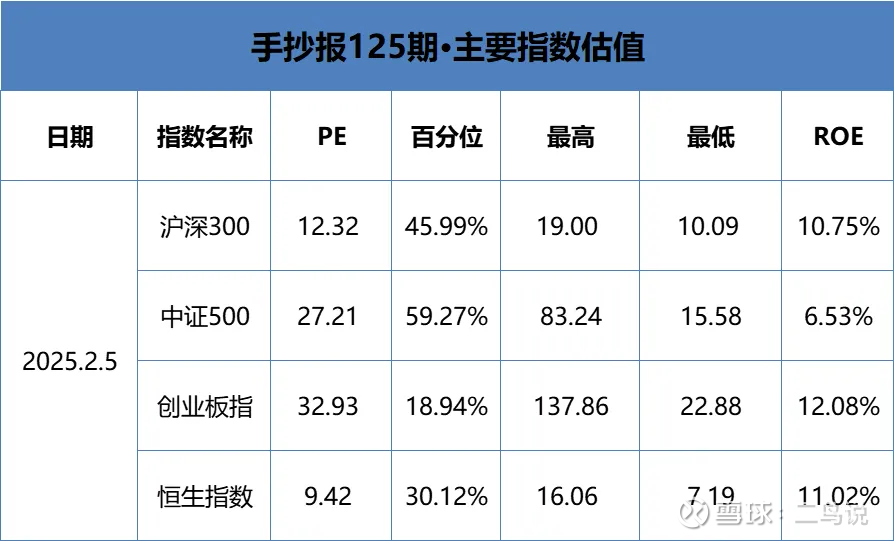
|
二鸟说 · -20250207121736 5 月前 |